
虽然有点晚了,但是还是分享一下之前折腾的本地运行一个大语言模型(LLM)语音助手的过程~
做这个来源于在推上看到有人分享了使用大语言模型搭建的语音助手,刚好也想试试大语言模型相关的库和代码什么的。
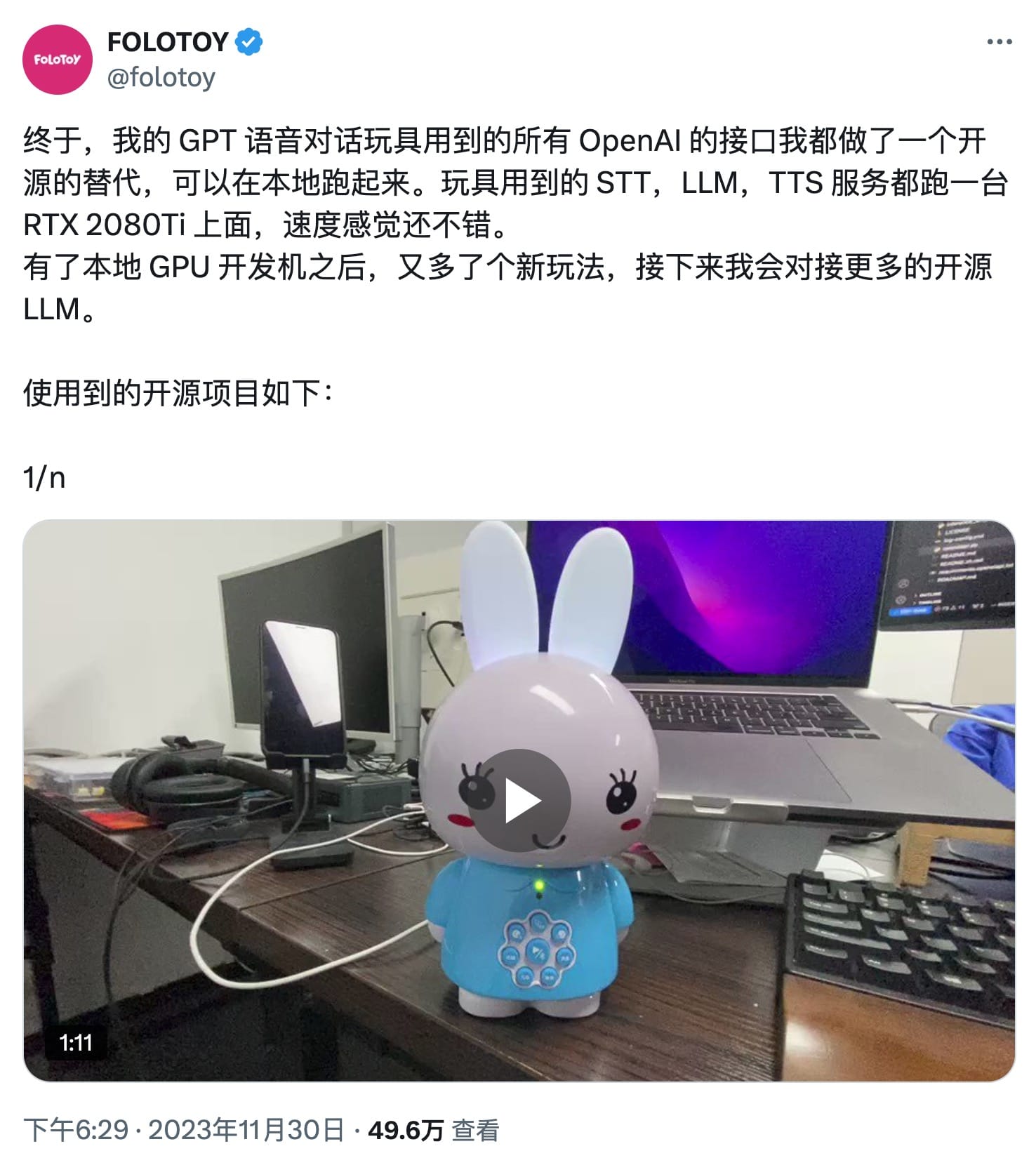
然后我参照推主的介绍,也使用相关的框架搭建了一个本地的语音助手,不过因为没有 GPU 以及测试的时候小参数量的大语言模型也不是很好用,因此 LLM 这块是使用的 OpenAI 的 API。
整体介绍
这个语音助手主要使用以下几个框架和服务:
- snowboy:用于声音检测、声音录制等功能,并且还支持静音检测(VAD)
- faster-whisper:用于语音转文本,这个是使用了 OpenAI 的 whisper 模型,并且重新实现的库,速度比官方的快很多
- SpeechRecognition:用来进行录音,在使用 snowboy 识别到唤醒词后,就用这个库来将后续的对话进行录制,交给 whisper 语音转文本
- EmotiVoice:文本转语音,将用户的对话内容通过 API 询问 GPT 之后,再将返回的文本内容生成语音并播放
- OpenAI:用来分析用户的对话并给出对应的回答
其中 fast-whisper 如果想要速度快的话,最好还是要有 Nvdia 的 GPU,使用 CPU 的话速度会慢不少,不过我在 M1 MacBook 上测试勉强能用。
snowboy
项目主页:https://github.com/Kitt-AI/snowboy
…Snowboy is a customizable hotword detection engine
阅读全文 »

近期评论