文章目录
前言
继续尝试复刻小智 AI,但是是基于 Arduino 框架。
上周把 VSCode + PlatformIO + Arduino 进行 ESP32-S3 + ESP-SR + ESP-TTS 的开发环境折腾完了,主要的语音唤醒、命令识别、文本转语音功能都跑通了,后面可以开始对接小智 AI 服务端的 WebSocket 协议了。
不过原作者的 78/xiaozhi-esp32 项目稍微复杂一点,阅读起来不太方便,而且也不太想搞 IDF 编译环境,就想找看有没有其他平台的实现,然后还真找到了一个 huangjunsen0406/py-xiaozhi 项目,是 Python + PyTk 编写的带界面的桌面客户端,而且它支持手动对话以及自动对话模式切换,可以顺便学习一下 PC 上的轻量级语音识别。
通信过程
小智 AI 客户端与服务端,可以使用 WebSocket 或者 MQTT 协议,这里为了方便就直接用 WebSocket 协议来学习了。
协议概述
在小智 AI 的通信过程中,WebSocket 用于实现客户端和服务器之间的实时、双向通信。主要传输以下类型的数据:
- 控制指令: 如开始/停止监听、中断TTS等。
- 文本信息: 如 LLM 的响应、情绪指令、配置信息等。
- 音频数据:
- 客户端 -> 服务器: 录制的 Opus 编码音频流。
- 服务器 -> 客户端: TTS 生成的 Opus 编码音频流。
- 状态同步: 如 TTS 播放开始/结束。
通信主要使用两种格式:
- JSON: 用于传输文本、控制指令和状态信息。
- Binary: 用于传输 Opus 编码的音频数据。
建立连接
-
客户端发起连接:客户端根据配置中的
WEBSOCKET_URL向服务器发起 WebSocket 连接请求。 -
发送头部信息:在建立 WebSocket 连接时,客户端需要发送必要的 HTTP 头部信息,包括:
-
Authorization:Bearer <access_token>(配置中WEBSOCKET_ACCESS_TOKEN) -
Protocol-Version:1(协议版本号) -
Client-Id: 客户端标识 -
Device-Id: 设备标识(通过是设备 MAC 地址) -
目前以上几个字段,除了 Device-Id 需要客户端生成,其他的都是固定值,可以使用以下设置:
- "WEBSOCKET_URL": "wss://api.tenclass.net/xiaozhi/v1/",
- "WEBSOCKET_ACCESS_TOKEN": "test-token",
- "CLIENT_ID": "1dd91545-082a-454e-a131-1c8251375c9c",
-
-
服务器响应:服务器接受连接。
-
客户端发送
hello:连接成功建立后,客户端需要发送一个hello消息(JSON 格式)。hello_message = { "type": "hello", "version": 1, "transport": "websocket", "audio_params": { "format": AudioConfig.FORMAT, "sample_rate": AudioConfig.SAMPLE_RATE, "channels": AudioConfig.CHANNELS, "frame_duration": AudioConfig.FRAME_DURATION, } }这里会预置音频编码参数,不过问题不大,后面服务端会推送它能接受的设置。
-
服务器响应 hello:提供会话 ID 和可能的初始配置。
{ "type": "hello", "version": 1, "transport": "websocket", "audio_params": { "format": "opus", "sample_rate": 24000, "channels": 1, "frame_duration": 20 }, "session_id": "a1f81xs89" }注意:客户端必须存储
session_id用于后续所有需要会话标识的消息。注意2:这里需要使用
audio_params更新本地 Opus 编码设置。
服务端认证
在第一次连接到小智 AI 官方后台时,需要在控制台中添加设备。
添加设备的方式也很便捷,在客户端连接到服务端并发送第一条语音消息时,服务器会返回一条语音,并带一个 6 位数的验证码,可以在后台添加设备。
至此就完成了和小智 AI 服务端 WebSocket 连接的建立,可以开始后续对话流程了。
客户端消息
要与小智 AI 对话,一般需要由客户端主动发起对话流程,发送第一个音频数据,或者是唤醒词。
listen (JSON)
控制音频监听(录音)的状态。
-
开始监听:
{ "session_id": "session-id", "type": "listen", "state": "start", "mode": "manual" | "auto" | "realtime" // 监听模式 } -
停止监听:
{ "session_id": "session-id", "type": "listen", "state": "stop" }
wake_word (JSON)
如果是通过唤醒词开始对话,要使用另外一个类型的 listen 消息,通知服务器检测到了唤醒词,这样服务端会立即返回一条语音消息。
-
格式:
{ "session_id": "session-id", "type": "listen", "state": "detect", "text": "你好小智" // 根据实际唤醒词修改 }
abort (JSON)
请求服务器中断当前正在进行的操作(主要是 TTS 语音播放)。
-
格式:
{ "session_id": "session-id", "type": "abort", "reason": "wake_word_detected" // (可选) 中断原因 }
这个主要是在小智 AI 服务端输出一段长语音但是又想重新开始新对话时使用。
audio (Binary)
发送录制的音频数据。
- 格式: 二进制数据帧 (Binary Frame)。
- 内容: 根据
session_info中audio_config约定的格式(默认为 Opus)编码的音频数据块。
IoT 消息
这块暂时不玩,以后再研究具体格式。
服务端消息
小智 AI 服务端返回的消息类型也分 JSON 和 Binary,其中 JSON 类型消息依赖 type 字段来区分实际内容。
示例 JSON 消息格式:
{
"type": "tts",
"state": "start",
"sample_rate": 24000,
"session_id": "session-id"
}其中 type 字段用来标识消息类型,有 llm、tts、stt 等。
type=tts (JSON)
这个消息就是小智 AI 服务端返回的主要消息类型了,包括情绪、语音播放、语音转文本,都是在这个类型的消息中返回的。
可以说小智 AI 的整个交互流程中,主要的工作量都是由服务端完成了,客户端的实现都可以比较轻量。
在 type=tts 类型的消息中,根据 state 字段的不同,也需要针对性的进行处理。
state=start
小智 AI 服务端在收到客户端的语音数据后,生成了对应的 LLM 聊天对话内容,开始返回 语音数据,这里也同样给了一个音频数据 sample_rate 参数,可以同步更新播放配置。
{
"type": "tts",
"state": "start",
"sample_rate": 24000,
"session_id": "session-id"
}state=sentence_start
小智 AI 返回的对话中一句话的开始,text 字段包含了所说语音的文本内容。
{
"type": "tts",
"state": "sentence_start",
"text": "感觉你心情不太好,发生了什么事吗?",
"session_id": "session-id"
}
state=sentence_end
小智 AI 返回的对话中一句话的结束。
{
"type": "tts",
"state": "sentence_end",
"text": "感觉你心情不太好,发生了什么事吗?",
"session_id": "session-id"
}
state=stop
小智 AI 对于之前收到的语音,生成的响应内容已经整体结束,客户端可以继续进行录音操作。
{
"type": "tts",
"state": "stop",
"session_id": "session-id"
}
type=llm (JSON)
这个消息返回了大模型在回复时所需要表达的情绪,text 是一个 Emoji 表情,emotion 对应了情绪的单词,在不能显示 Emoji 的设备上,可以由单词去对应到图片进行展示。
{
"type": "llm",
"text": "🤔",
"emotion": "thinking",
"session_id": "session-id"
}
emotion 可选的值如下:
static const std::vector<Emotion> emotions = {
{"😶", "neutral"},
{"🙂", "happy"},
{"😆", "laughing"},
{"😂", "funny"},
{"😔", "sad"},
{"😠", "angry"},
{"😭", "crying"},
{"😍", "loving"},
{"😳", "embarrassed"},
{"😯", "surprised"},
{"😱", "shocked"},
{"🤔", "thinking"},
{"😉", "winking"},
{"😎", "cool"},
{"😌", "relaxed"},
{"🤤", "delicious"},
{"😘", "kissy"},
{"😏", "confident"},
{"😴", "sleepy"},
{"😜", "silly"},
{"🙄", "confused"}
};type=stt (JSON)
这个是小智 AI 服务端由客户端发送的语音识别出来的文本,可以显示在屏幕上展示双方完整的对话内容。
{
"type": "stt",
"text": "今天天气怎么样",
"session_id": "session-id"
}type=iot (JSON)
和客户端消息一样,这个现在还没研究,以后再看看。
audio (Binary)
小智 AI 服务端发送的 TTS 音频数据。
- 格式: 二进制数据帧 (Binary Frame)。
- 内容: 根据
hello消息中audio_params约定的格式(默认为 Opus)编码的 TTS 音频数据块。客户端接收后应立即进行解码和播放。
核心交互流程图
手动对话交互流程

自动对话交互流程图
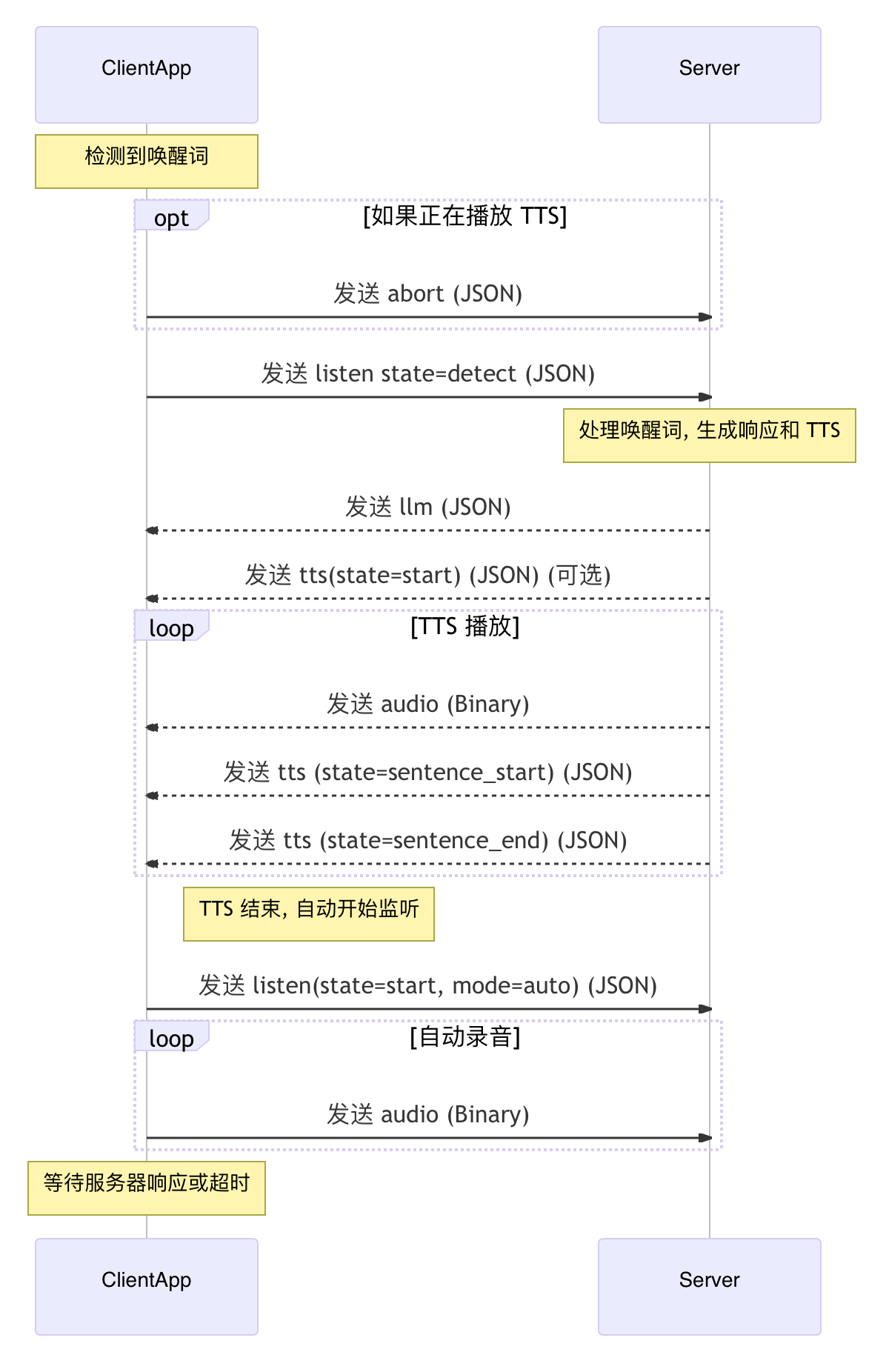
异常处理
服务端主动断开连接
在跟小智 AI 说“再见”的时候,服务端会主动断连接,因此在这个时候,如果重新开始了手动对话,或者使用唤醒词触发对话,就需要重新连接服务器。
网络异常
网络异常时,按正常初始化流程重新连接 WebSocket 即可。
总结
整体来说,小智 AI 的通信协议还是比较简单的,大概理了一遍之后,也能用 Cursor + AI 快速搞一个 Python 版本的客户端出来,后面再对接一下 ESP32 试试。
另外,这里的流程和消息是参考了官方仓库和实际交互过程的报文总结的,可能会存在不准确的地方,如果有错误,欢迎指正。

0 条评论。